Single Prediction Workflow
The Single Prediction Workflow in Gesund.ai outlines the backend process that handles a single prediction request using a deployed model. This high-level overview explains each step involved—from the user request to the model response—ensuring transparent and trackable prediction execution.
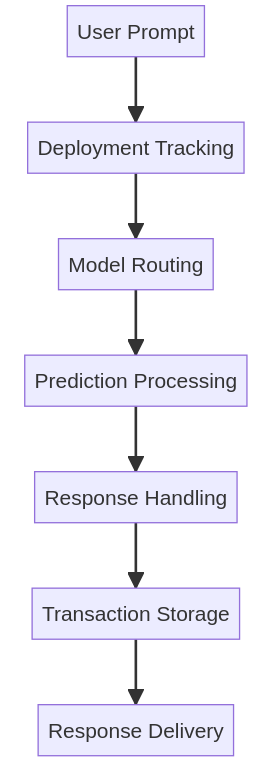
1. User Request
The workflow begins when a user sends a prediction request through the platform interface. The request must include:
- The Deployment ID of the selected model.
- Input image data for which a prediction is to be made.
2. Deployment Tracking
The platform uses the Deployment ID to retrieve tracking information:
- Identifies which model is linked to the request.
- Determines whether the deployment is a standard model or a custom image-based model.
3. Model Routing
Routing depends on the deployment type:
- For custom deployments, the platform sends the request directly to the custom model API.
- For standard deployments, the request is published to a RabbitMQ queue, which manages communication with the appropriate model.
4. Prediction Processing
The model processes the request and returns the output:
- In custom deployments, the API returns the result directly.
- In standard cases, the RabbitMQ worker processes the image and provides the prediction result.
5. Response Handling
Once the model returns a result:
- If the request includes (explain_params), the platform adds explanation metadata (e.g., attention maps, confidence details).
- If not, a standard prediction output is returned.
6. Transaction Storage
The platform logs the entire transaction, including:
- Deployment and model info.
- Prediction metadata.
- Timestamps and user request context.
This ensures traceability and enables future audit or debugging if needed.
7. Response Delivery
Finally, the platform sends the prediction response back to the user interface:
- This can include either the raw prediction or extended outputs (if explanations were requested).
- The result is now available for the user to view, analyze, or export.
Note: This workflow supports both real-time predictions and robust backend tracking, ensuring reliability and reproducibility of results across sessions.