Dataset Analysis
The Dataset Analysis page enables users to explore a dataset through statistical insights and visual analysis tools. It helps uncover class imbalances, duplicates, noisy labels, and distribution anomalies — all crucial for dataset validation and preparation.
Navigation & Layout
The page includes a top menu with:
- A dataset selector dropdown to switch between datasets.
- A shortcut button to view dataset details.
- Pagination and filtering controls in each tab for efficient navigation.
Tabs Overview
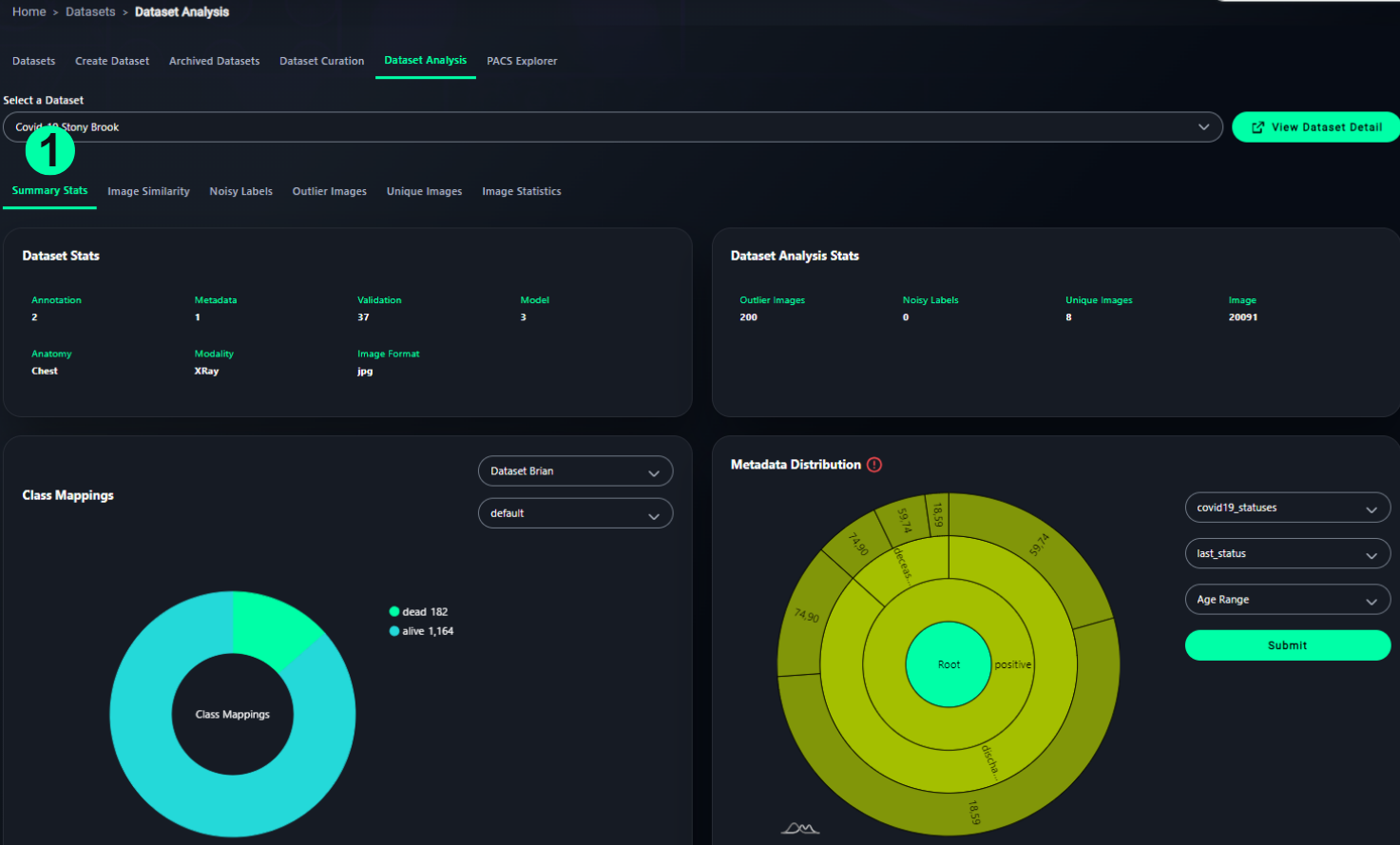
1. Summary Stats
- Displays total counts for:
- Images
- Annotations
- Metadata records
- Linked validation models
- Shows insights like:
- Number of outliers, noisy labels, and unique images
- Class Mappings: Pie or donut chart for label distribution (e.g., 'Alive' vs 'Dead')
- Metadata Distribution: Sunburst chart illustrating fields like age or COVID-19 status
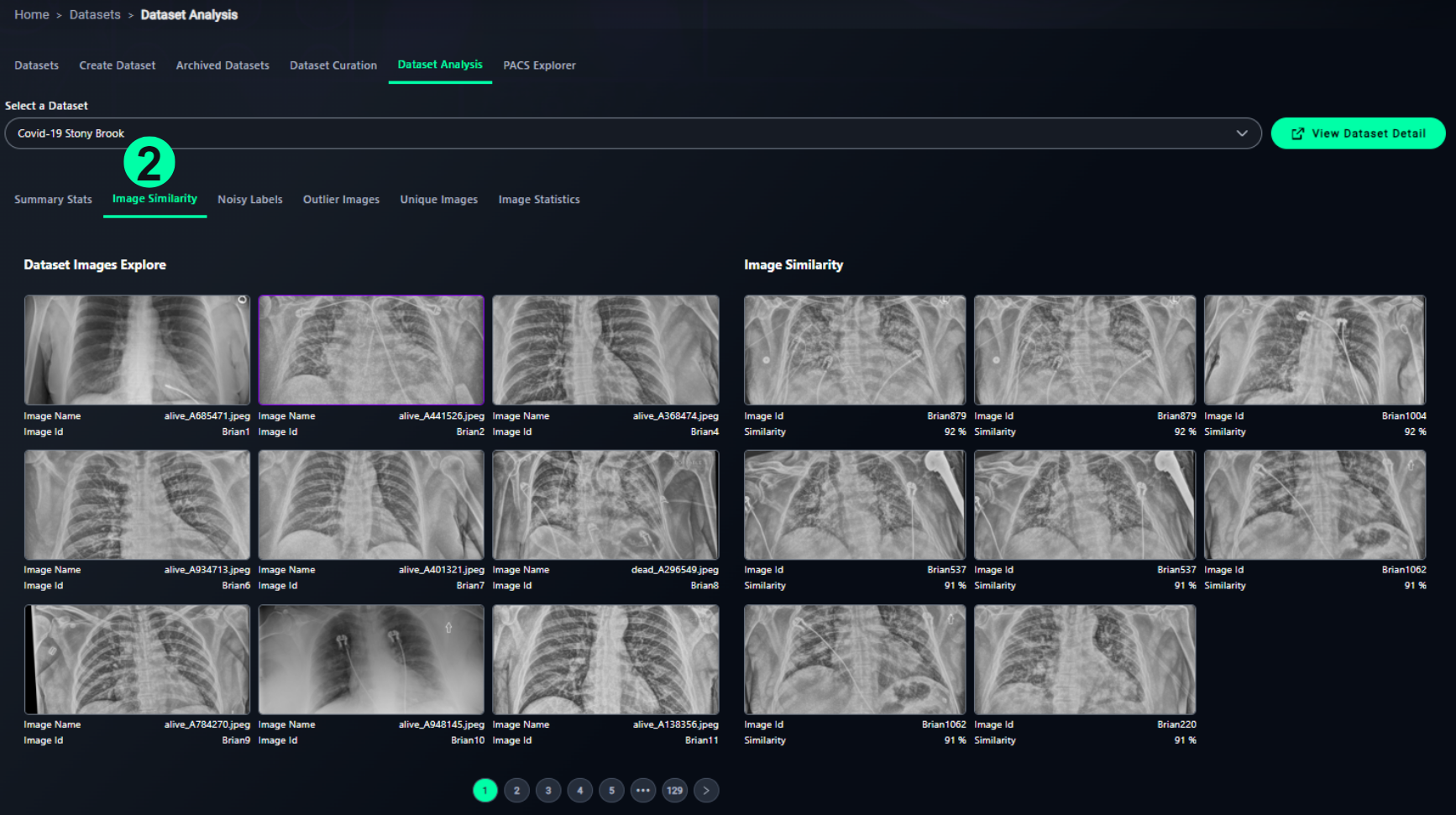
2. Image Similarity
- Clusters visually similar images
- Grid view of groups with similarity scores
- Allows users to:
- Identify potential duplicates
- Explore similarity-based edge cases
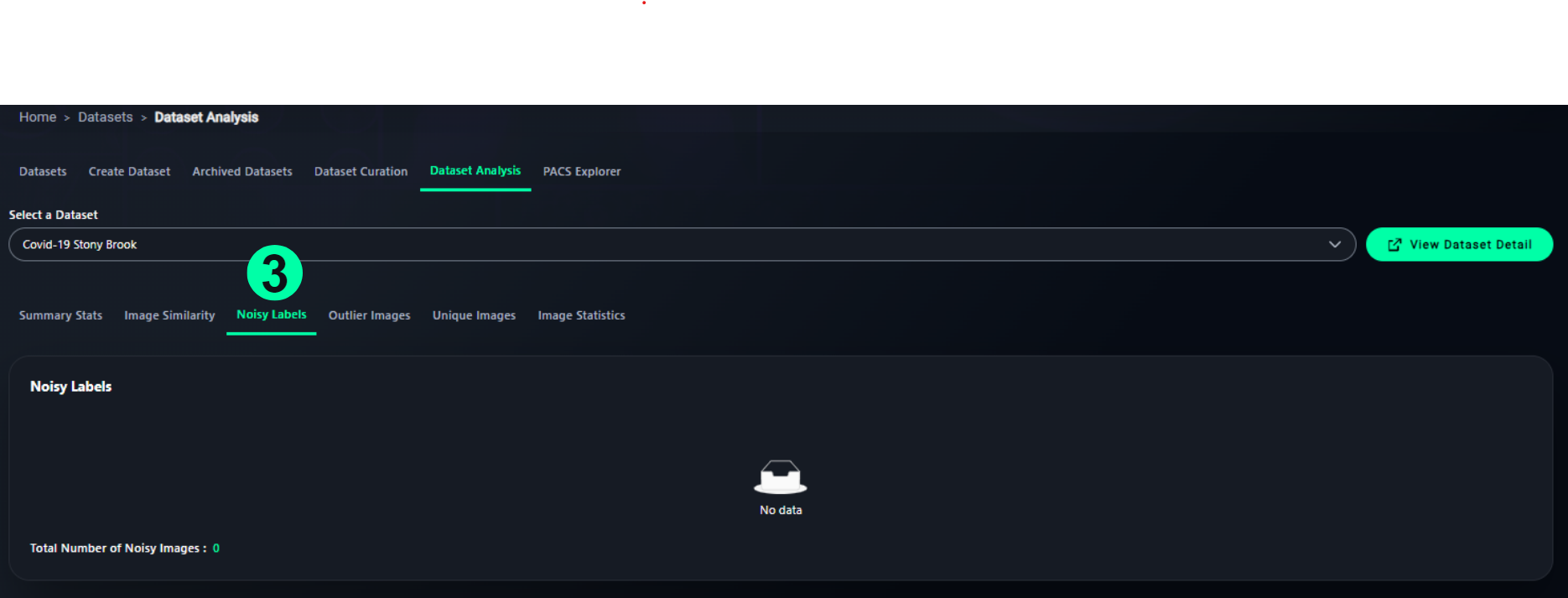
3. Noisy Labels
- Highlights images with inconsistent or suspicious labels
- Shows count of noisy images
- If none detected, the UI displays an informative placeholder
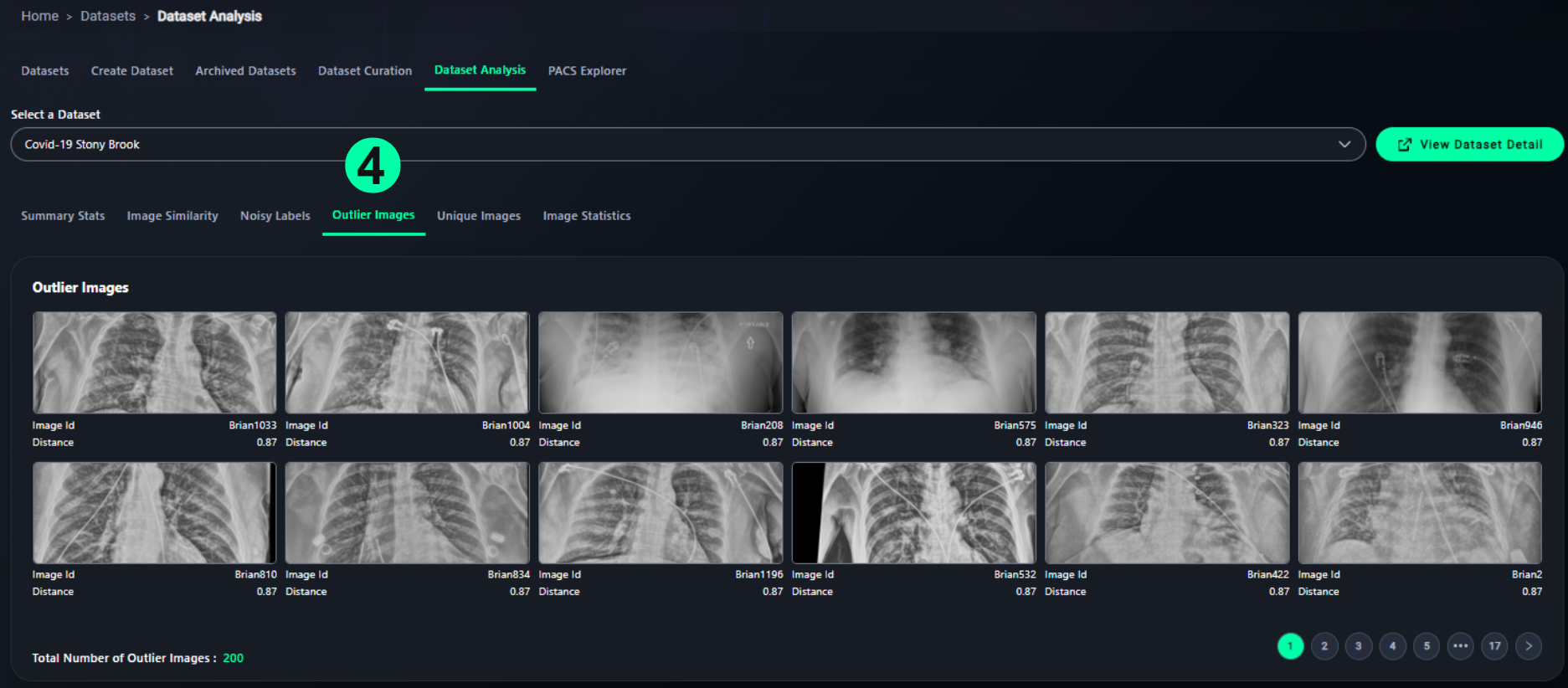
4. Outlier Images
- Detects images statistically distant from dataset norms
- Each image includes:
- Internal ID
- Distance metric value
- Total outlier count is displayed
📸 
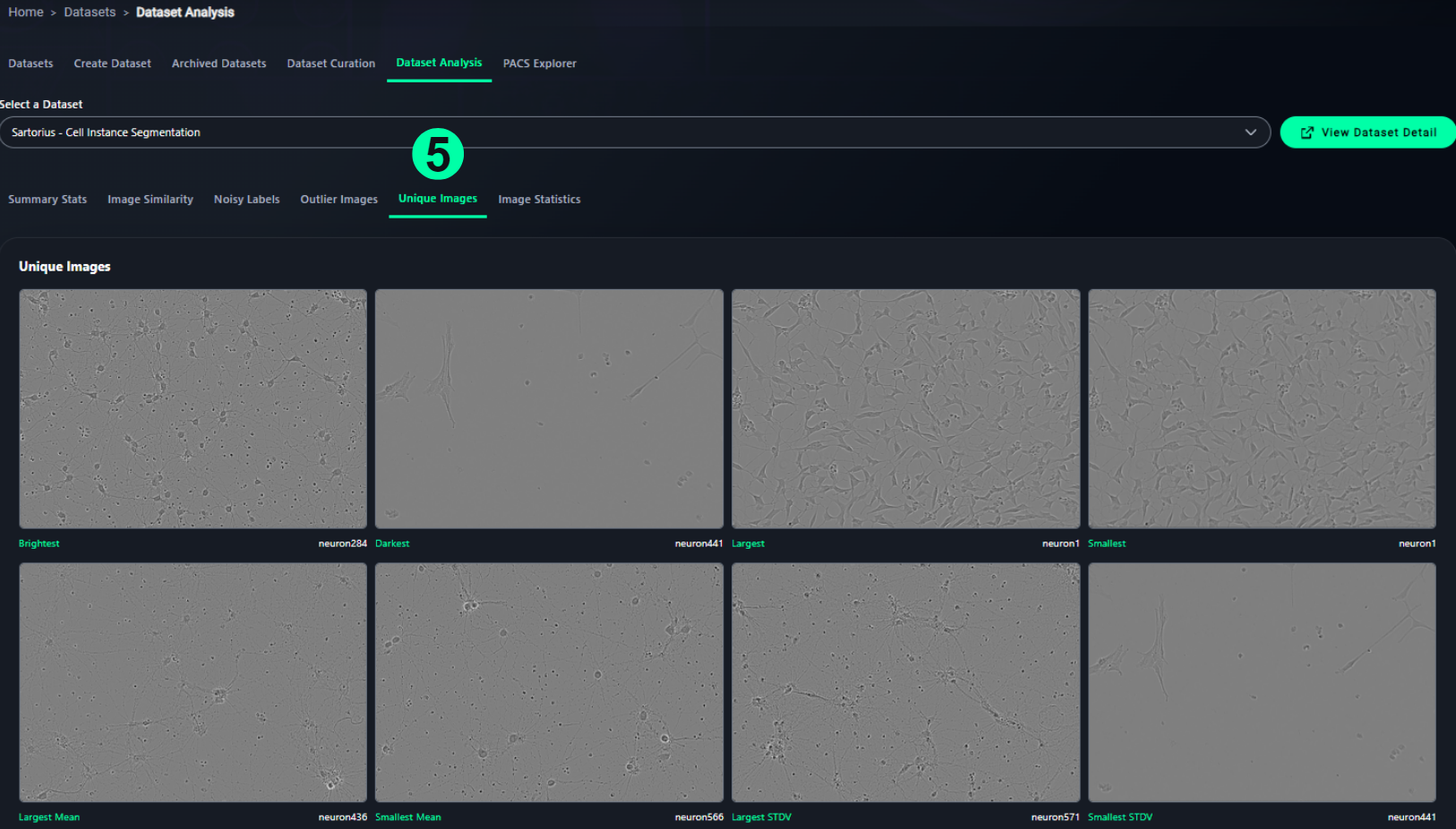
5. Unique Images
- Categorizes standout images based on brightness, size, and pixel distribution:
- Brightest / Darkest
- Largest / Smallest
- Largest/Smallest Mean
- Largest/Smallest Standard Deviation (STDV)
📸 
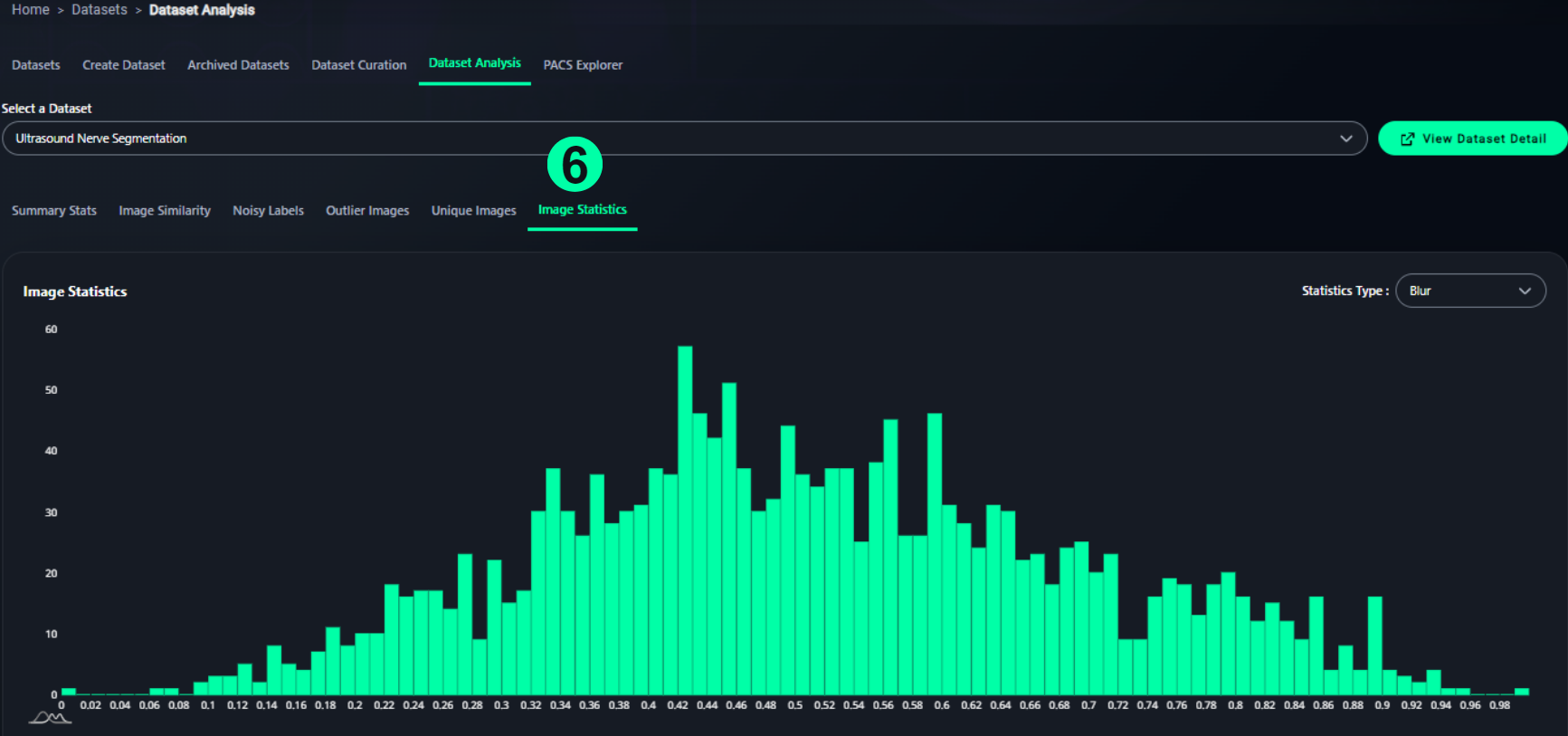
6. Image Statistics
- Graphical overview of pixel-level statistics:
- Blur
- Brightness
- Contrast
- Others (selectable from dropdown)
- Line chart shows distribution across the dataset
📸 
Why Use This?
- Ensure data quality before model training
- Spot anomalies and cleaning opportunities
- Visualize label balance and image metadata spread
- Evaluate dataset uniqueness to avoid overfitting
This toolset is critical for validating medical datasets and improving AI readiness.